Use transformer in Julia
I’m trying to follow Kasper Groes Albin Ludvigsen’s post <How to make a Transformer for time series forecasting with PyTorch> to use transformer in time series prediction. However, I will use Julia instead of Pytorch. Full code can be found in my repo in GitHub.
The model can be coded easily using the 2 Julia packages: Flux, and Transformers.jl.
Model building
Here is the code for transformer encoder and decorder:
begin#define 2 layer of transformer
encode_t1 = Transformer(dim_val, n_heads, 64, 2048;future=false,pdrop=0.2)|> gpu
encode_t2 = Transformer(dim_val, n_heads, 64, 2048;future=false,pdrop=0.2)|> gpu#define 2 layer of transformer decoder
decode_t1 = TransformerDecoder(dim_val, n_heads, 64, 2048,pdrop=0.2) |> gpu
decode_t2 = TransformerDecoder(dim_val, n_heads, 64, 2048,pdrop=0.2) |> gpuencoder_input_layer = Dense(input_size,dim_val) |> gpu
decoder_input_layer = Dense(input_size,dim_val) |> gpu
positional_encoding_layer = PositionEmbedding(dim_val) |> gpup = 0.2
dropout_pos_enc = Dropout(p) |> gpulinear = Dense(output_sequence_length*dim_val,output_sequence_length) |> gpufunction encoder_forward(x)
x = encoder_input_layer(x)
e = positional_encoding_layer(x)
t1 = x .+ e
t1 = dropout_pos_enc(t1)
t1 = encode_t1(t1)
t1 = encode_t2(t1)
return t1
endfunction decoder_forward(tgt, t1)
decoder_output = decoder_input_layer(tgt)
t2 = decode_t1(decoder_output,t1)
t2 = decode_t1(decoder_output,t2)
t2 = Flux.flatten(t2)
p = linear(t2)
return p
endend
The Transformers package has the built-in position embedding layer, so I don’t need to code myself. Besides, I don’t need to construct the mask myself because the transformer layer has already built in the parameter: future. When future is false, the k-th token can't see the j-th tokens where j > k.
Data Preparation
Each training data sample is a sub-sequence of the time series. Here is the function to extract each sub-sequence of length seq_len by shifting x right each time.
function generate_seq(x, seq_len)
result = Matrix{Float64}[]
for i in 1:length(x)-seq_len+1
ele = reshape(x[i:i+seq_len-1],(seq_len,1))
push!(result,ele)
end
return result
endThen, I follow Kasper’s post to break each sub-sequence into 3 parts: encoder-sequence (src), decoder-sequence (trg), and target-sequence (trg_y).
function get_src_trg(sequence, enc_seq_len, dec_seq_len, target_seq_len)
nseq = size(sequence)[2]
@assert nseq == enc_seq_len + target_seq_len
src = sequence[:,1:enc_seq_len,:]
trg = sequence[:,enc_seq_len:nseq-1,:]
@assert size(trg)[2] == target_seq_len
trg_y = sequence[:,nseq-target_seq_len+1:nseq,:]
@assert size(trg_y)[2] == target_seq_len
if size(trg_y)[1] == 1
return src, trg, dropdims(trg_y; dims=1)
else
return src, trg, trg_y
end
endModel Training
Here is the training loop code. Half of the data is for training, and the other half is for verification testing in prediction.
function loss(src, trg, trg_y)
enc = encoder_forward(src)
dec = decoder_forward(trg, enc)
err = Flux.Losses.mse(dec,trg_y)
return err
end
lg=TBLogger("tensorboard_logs/run", min_level=Logging.Info)data = generate_seq(values(ta_mv[:"10 YR"]),enc_seq_len+output_sequence_length)
data = reduce(hcat,data)
data = convert(Array{Float32,2}, data)
data_sz = size(data)
thd = floor(Int,data_sz[2]/2)
testdata = data[:,thd+1:end]
data = data[:,1:thd]ps = params(encoder_input_layer, positional_encoding_layer, encode_t1, encode_t2, decoder_input_layer, decode_t1,decode_t2, linear)all_layers = [ encoder_input_layer, positional_encoding_layer, encode_t1, encode_t2, decoder_input_layer, decode_t1, decode_t2, linear ]opt = ADAM(1e-4)
train_loader = Flux.Data.DataLoader(data, batchsize=32)l = 100
for i = 1:1000
for x in train_loader
sz = size(x)
sub_sequence = reshape(x,(1,sz[1],sz[2]))
src, trg, trg_y = get_src_trg(sub_sequence, enc_seq_len, dec_seq_len, output_sequence_length)
src, trg, trg_y = todevice(src, trg, trg_y) #move to gpu
grad = gradient(()->loss(src, trg, trg_y), ps)
Flux.update!(opt, ps, grad)
global l = collect(loss(src, trg, trg_y))[1]
if l < 1e-3
continue
end
end
if i % 10 == 0
for (j,layer) in enumerate(all_layers)
@save "checkpoint/model-"*string(j)*".bson" layer
end
with_logger(lg) do
@info "train" loss=l log_step_increment=1
end
endif l < 1e-3
continue
endend
Prediction Testing
Here is the function for model prediction with the sub-sequence ix, where the encoder input (ix[:,1:enc_seq_len,:]), and decoder input by shifting the target by 1 left (ix[:,enc_seq_len:sz[1]-1,:]) were fed into the encoder_forward and decoder_forward to predict the last value (dec[end,:]) in the sequence.
function prediction(test_data)
seq = Array{Float32}[]
test_loader = Flux.Data.DataLoader(test_data, batchsize=32)
for x in test_loader
sz = size(x)
sub_sequence = reshape(x,(1,sz[1],sz[2]))
ix = sub_sequence[:,1:enc_seq_len+output_sequence_length,:]
ix = todevice(ix)
enc = encoder_forward(ix[:,1:enc_seq_len,:])
trg = ix[:,enc_seq_len:sz[1]-1,:]
dec = decoder_forward(trg, enc)
seq = vcat(seq,collect(dec[end,:]))
end
return seq
endTest 1 with sin curve
First, I tried to verify the model with simple sin curve data, which it should be predicted well.
sincurve1 = Vector{Float64}()
for i in 1:500
append!(sincurve1,sin(i))
enddata = generate_seq(sincurve1,enc_seq_len+output_sequence_length)
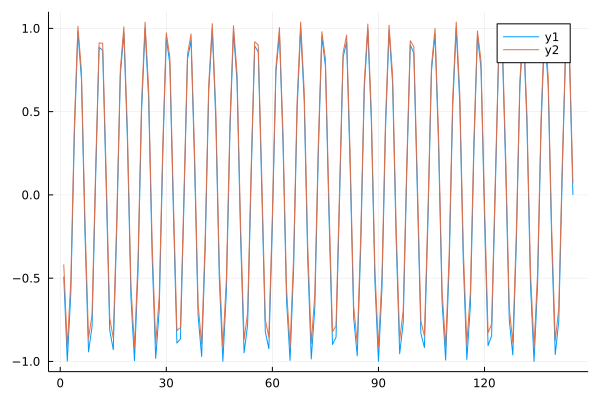
Both the predicted value and actual value are well fit each other. The result is good.
Test 2 with interest rate data
I would like to use the actual data to test the model. The data I use is the 10-year daily treasury real yield downloaded since 2003 from the US Treasury. I use 15-day moving average to smoothen the data.
ta = readtimearray("rate.csv", format="mm/dd/yy", delim=',')
ta_mv = moving(mean,ta,15)
data = generate_seq(values(ta_mv[:"10 YR"]),enc_seq_len+output_sequence_length)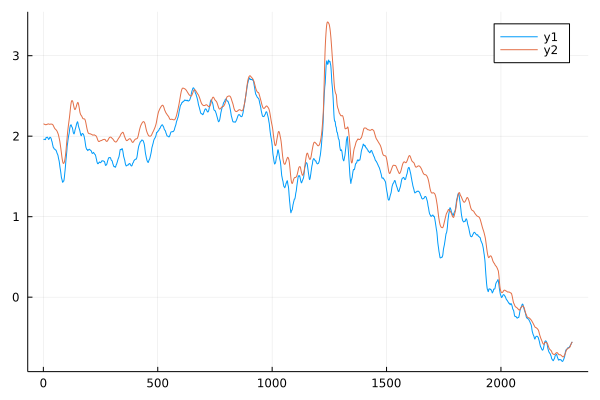
Both the predicted value (blue) and actual value (red) are well fit each other. The result is good.
Test 3 with stock price data
Trying to predict the stock price which is more volatile than interest rate. I use the Julia Package MarketData to get the daily closing stock price. Again, I smoothen the data by taking 15-day moving average.
data = generate_seq(values(moving(mean,cl,15)),enc_seq_len+output_sequence_length)Both the predicted value (blue) and actual value (red) are not well fit each other. The result is not good.
